
W bazie danych Oracle jednym z ciekawych i bardzo popularnych metod złączeń jest HASH JOIN. W poprzednim kursie opisywałem podstawową metodę łączenia dwóch tabel jaką jest nested loops join. W kursie tym opisałem, że nested loops join przy przeszukiwaniu dużych zbiorów (a dokładniej dużych części zbiorów) jest niewydajną metodą złączenia. Hash join jest natomiast metodą która działa sprawnie przy przeszukiwaniu większej ilości danych (większych zbiorów z tabel).
Ten kurs jest częścią Kurs Oracle SQL
W tym kursie opiszę:
- Jak działa HASH JOIN
- Przykład działania HASH JOIN
- Dlaczego HASH JOIN jest szybszy dla dużych zbiorów danych?
- Przedstawię przykłady wywołania HASH JOIN wraz z planami
- Pokażę Hint do wymuszenia HASH JOIN
- Przedstawię wady HASH JOIN
- Podsumowanie
Jak działa HASH JOIN?
Metoda HASH JOIN jest wybierana przez optymalizator w sytuacji gdy chcemy połączyć dwie tabele i chcemy złączyć duży zestaw danych a w szczególności gdy pobieramy sporą część danych z obu tabel. Hash join w skrócie działa następująco:
- Baza wybiera mniejszy zestaw danych i tworzy dla niej funkcję skrótów (hash)
- Następnie baza z drugiej tabeli wybiera pojedyncze rekordy, liczy dla nich skrót(hash) i porównuje z tabelą skrótów.
Przykład działania HASH JOIN
W tej części przedstawię krok po kroku działanie HASH JOIN na podstawie konkretnego przykładu. Cały proces postaram się pokazać na przykładzie z danymi.
Poniżej przedstawiam przykładową bazę danych składającą się z dwóch tabel:
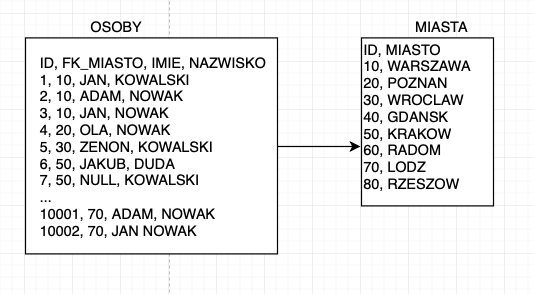
Mamy tu dwie tabele:
- OSOBY – tabela z trzema kolumnami: ID, FK do tabeli miasto, IMIE i NAZWISKO. Łącznie 10 tyś rekordów
- MIASTA – tabela z dwoma kolumnami: ID oraz MIASTO. Załóżmy, że ok 8 rekordów.
Wyobraźmy teraz sobie proste zapytanie ze złączeniem jakie możemy wykonać na takiej bazie:
SELECT
*
FROM OSOBY O
JOIN MIASTA M ON M.ID = O.FK_MIASTO;Czyli zapytanie po prostu łączące obie te tabele 🙂
Co się więc zadzieje w bazie?
W pierwszej kolejności baza na podstawie statystyk wybiera mniejszy zestaw danych. Zestaw danych rozumiem tutaj jako rekordy z tabeli po przefiltrowaniu i spełnieniu np. predykatów z warunków WHERE. Dlatego też większa tabela może dać finalnie do złączenia mniejszą ilość danych jeżeli jest bardziej ograniczona. W naszym przykładzie mniejszy zestaw danych reprezentowany jest przez tabelę MIASTA.
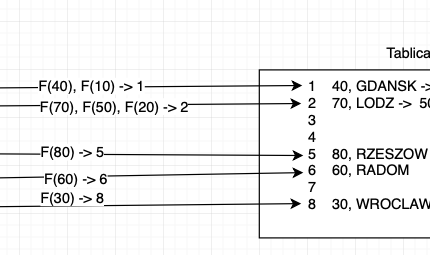
Baza określa ilość rekordów tabeli mniejszej i tworzy dla kluczy złączenia tablicę skrótów (Oracle nazywa ją build table). Proces tworzenia tabeli skrótów wygląda mniej więcej jak na poniższym schemacie:
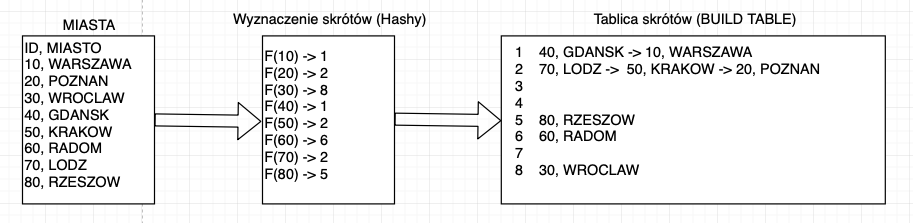
Co więc widzimy na powyższym schemacie i co oznaczają które kroki?
Dla każdego ID tabeli MIASTA wyznaczana jest wartość funkcji skrótu czyli wartość odpowiadającą ID. Zauważyć można, że niektóre wartości jak np. 10, 40 czy 20, 50, 70 dają tą samą wartość hash. Po dokładniejszy opis czym jest hash odsyłam do wikipedii. Wiedzieć należy jednak, że funkcje haszujące mogą zwracać ten sam hash dla różnych wartości.
Po wyznaczeniu wartości hash dla każdego z ID baza tworzy tablicę skrótów (build table). Tablica skrótów tworzona jest z wartości hash oraz rekordów jej odpowiadających. Baza danych dla tych samych wartości hasha składa je w listę kolejnych elementów.
Gdy baza zbuduje tablicę hashy zaczyna w pętli łączyć kolejne rekordy. Schemat łączenia zaprezentowałem poniżej:
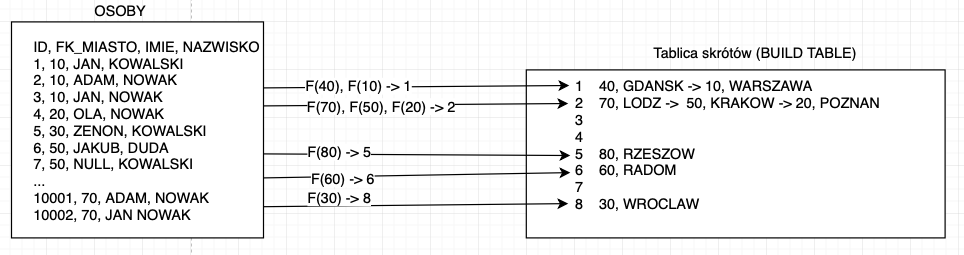
Baza danych wykonuje pętlę po tabeli OSOBY i wyznacza dla każdego rekordu wartość funkcji skrótu dla warunku złączenia i łączy rekordy. Dla przykładu rekord z ID=1 zwróci hash = 1 co odpowiada pierwszemu rekordowi z tabeli skrótów. Gdy baza natrafi w tablicy skrótów na listę porównuje bezpośrednie identyfikatory aż znajdzie odpowiadającą wartość. Dla ID=5 baza zwróci hash=8 i od razu przekieruje na ostatni rekord z tablicy skrótów i tak dalej aż przeszuka przez wszystkie rekordy w tabeli OSOBY.
Dlaczego HASH JOIN jest szybki dla dużych zbiorów danych?
Gdyby popatrzyć na przykład z powyższymi danymi można się zastanowić czy aby na pewno HASH JOIN jest w jakikolwiek sposób skuteczny przy łączeniu tabel. Wpierw jedną tabelę należy przeskanować, przeliczyć wartości hash. Następnie przejrzeć drugą tabelę, przeliczyć wartość hash dla każdego rekordu. Sprawdzić czy nie jest to lista, jeżeli jest, to przeszukać ją aż znajdziemy odpowiednią wartość, dopiero złączyć i zwrócić wynik. Gdzie jest więc uzysk?
Tak więc najważniejszą zaletą wykorzystania funkcji skrótu jest fakt, że po jego przeliczeniu baza danych nie musi iterować po tabeli a od razu trafia na odpowiedni rekord w tabeli skrótów (hash table lub build table). Oznacza, to że jeżeli baza danych dla rekordu z ID=5 z przykładu wyznaczy hash = 8 nie musi iterować po wszystkich wartościach a od razu łączy z rekordem z wartością 30 Wrocław. Zamiast wykonać 8 operacji sprawdzenia wykonuje jedną. Im większe tabele tym większa przewaga HASH JOIN nad NESTED LOOPS JOIN.
Przykłady wywołania HASH JOIN wraz z planami
Opisałem już jak działa HASH JOIN więc nadszedł moment na wykonanie kilku planów zapytania i porównanie HASH JOIN do innych metod łączenia dwóch tabel. Do testów wykorzystam tych samych danych co w kursie JOIN NESTED LOOPS, więc najpierw utwórzmy dwie tabele:
CREATE TABLE FOO_TABLE (
ID NUMBER
, FOO VARCHAR2(255 CHAR)
, CONSTRAINT ID_FOO_TABLE_PK PRIMARY KEY (ID)
);
CREATE TABLE BAR_TABLE (
FOO_ID NUMBER
, BAR VARCHAR2(255 CHAR)
);Następnie wypełnijmy je danymi w liczbie po 10000 rekordów tak, że pasują jeden do jednego przy pomocy poniższego skryptu PL/SQL:
BEGIN
FOR I IN 0 .. 10000
LOOP
INSERT INTO FOO_TABLE (
ID
, FOO
) VALUES (
I
, 'FOO ' || I
);
END LOOP;
END;
/
BEGIN
FOR I IN 0 .. 10000
LOOP
INSERT INTO BAR_TABLE (
FOO_ID
, BAR
) VALUES (
I
, 'BAR ' || I
);
END LOOP;
END;
/
COMMIT;Oraz przeliczmy statystyki dla obu tabel:
EXEC DBMS_STATS.GATHER_TABLE_STATS('SYSTEM','FOO_TABLE');
EXEC DBMS_STATS.GATHER_TABLE_STATS('SYSTEM','BAR_TABLE');Skoro mamy już przygotowaną bazę danych do testów to wykonajmy najprostsze zapytanie:
SELECT
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON BAR.FOO_ID = FOO.ID
WHERE 1=1;oraz plan zapytania:

Na powyższym planie widzimy wykorzystanie HASH JOIN. Jako, że pobieramy dużą ilość rekordów z obu tabel to baza wykorzystała hash join.
Zobaczmy co się stanie gdy wyciągniemy z tabel niewielką ilość danych zgodnie z poniższym zapytaniem:
SELECT
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON BAR.FOO_ID = FOO.ID
WHERE 1=1
AND FOO.ID = 10;Oraz plan zapytania:
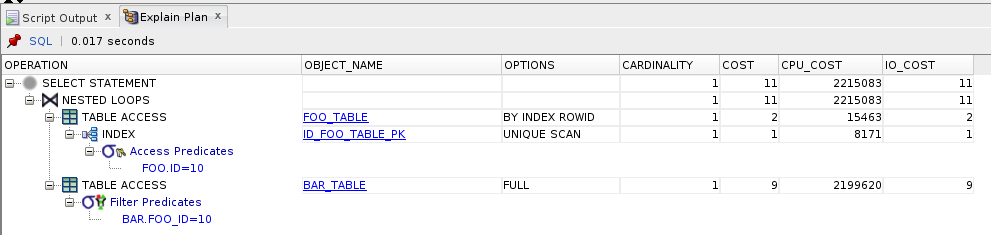
Na powyższym planie widzimy, że baza wybrała wykorzystanie NESTED LOOPS jako metodę złączenia zamiast HASH JOIN. Dzieje się tak, ponieważ pobieramy bardzo niewielką ilość rekordów dlatego też szybciej jest przeskanować wszystkie rekordy w obu tabelach w cel znalezienia odpowiednich rekordów niż budowa tablic skrótu.
Teoretycznie gdy z obu tabel pobieramy dużą ilość rekordów HASH JOIN będzie lepszą metodą łączenia tabel niż NESTED LOOPS. Kiedy HASH JOIN może być mało wydajny opisałem poniżej w części dotyczącej wad tej metody łączenia.
Hint HASH JOIN
Hint do wymuszenia HASH JOIN przy połączeniu dwóch tabel to: use_hash(nazwwa_tabeli_1, nazwa_tabeli_2).
Aby sprawdzić działanie hintu zobaczmy plan referencyjnego zapytania np.:
SELECT
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON BAR.BAR = FOO.FOO
WHERE 1=1
AND FOO.ID = 100;Oraz plan:

Zobaczmy więc to samo zapytanie z hitem user_hash:
SELECT
/*+ use_hash(FOO, BAR)*/
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON BAR.BAR = FOO.FOO
WHERE 1=1
AND FOO.ID = 100;Oraz plan:
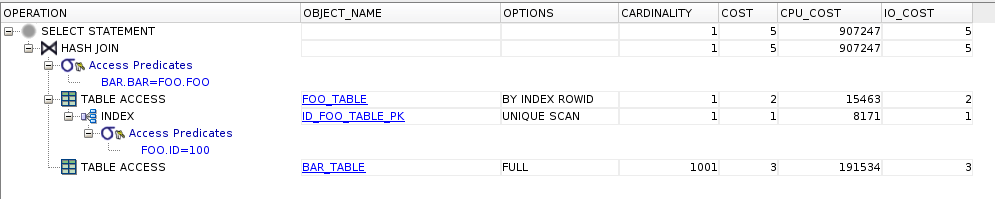
Plan wykonania wraz z HASH JOIN. Na planie nie widzimy wzrostu kosztu planu ponieważ tabele są niewielkie.
Mała uwaga odnośnie hintu use_hash. Przytrafiła mi się sytuacja, że baza nie wzięła go pod uwagę i pomimo hintu use_hash w planie widać nested loops join. Kilka testów pokazało, że baza nie weźmie hintu pod uwagę, jeżeli będziemy chcieli go wymusić na np. unique index który jest w warunku złączenia oraz w warunku where jak poniższe zapytanie:
SELECT
/*+ use_hash(FOO, BAR)*/
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON BAR.FOO_ID = FOO.ID
WHERE 1=1
AND FOO.ID = 100;Oraz plan:
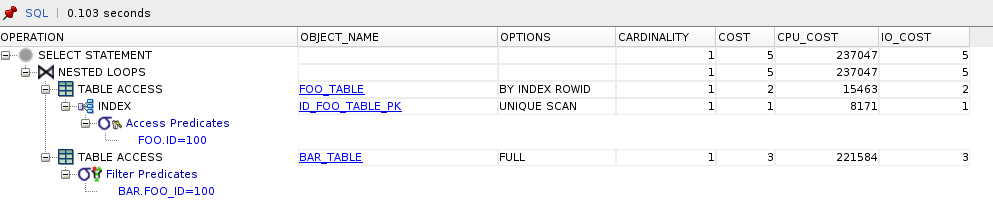
Dlaczego baza nie wzięła pod uwagę hintu? Tak naprawdę nie wiem i nie znalazłem nigdzie opisuje takiego przypadku ale domyślam się 🙂 A domyślam się, że powodem jest unikalność indexu oraz konstrukcja warunków. Nawet nie posiadając jakichkolwiek statystyk czy manipulując danymi na bazie unique index zawsze będzie posiadał unikalne wartości i z tabeli zewnętrznej zawsze znajdzie jeden rekord (dla powyższego zapytania). W wyniku czego NESTED LOOPS zawsze będzie szybsze od innych metod joinowania.
Wada HASH JOIN
Omawiana metoda joinowania ma jedną podstawową wadę. A jest nią fakt, że budowa tablicy hashy jest w pamięci PGA. O ile samo korzystanie z PGA nie jest niczym złym i nie jest żadną wadą to problem pojawia się, gdy tablica zaczyna być większa niż PGA. Wtedy to baza cześć tablicy hashy zaczyna zapisywać fizycznie na dysku a następnie w trakcie łączenia rekordów to czyta cześć danych z dysku to część na nim zapisuje tak aby mieścić się w PGA.
Czytanie danych z dysku jest zawsze znacznie wolniejsze niż działanie w pamięci. Gdy okaże się, że tablica hashy jest tak duża, że musi być zapisywana na dysku łączenie rekordów bardzo zwalnia.
Zobaczmy więc zużycie dla zapytania które użyliśmy dla bazy danych z przykładu i porównajmy hash join do nested loops join:
SELECT
/*+ use_nl(FOO, BAR)*/
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON FOO.ID = BAR.FOO_ID;
SELECT
/*+ use_hash(FOO, BAR)*/
*
FROM FOO_TABLE FOO
JOIN BAR_TABLE BAR ON FOO.ID = BAR.FOO_ID;Oraz wynik zużycia pamięci przy pomocy SQL:
SELECT
SQL_TEXT
, SHARABLE_MEM
, PERSISTENT_MEM
, RUNTIME_MEM
FROM V$SQL
WHERE 1 = 1
AND SQL_ID IN ('168mjsj1ybcrq', 'fnfh0q6v2vx2h');Oraz wynik:

Na powyższym wyniku widać znacznie większe zużycie pamięci przez zapytanie wykorzystujące hash join.
Podsumowanie
- HASH JOIN jest jedną z najwydajniejszych metod łączenia dużych zbiorów danych
- Tablica hashy tworzona jest na podstawie mniejszej tabeli
- Metod ta wykorzystuje duże zasoby pamięci
- Hint to USE_HASH(TABELA1, TABELA2)
Hej, mam pytanie odnośnie
“Tak więc najważniejszą zaletą wykorzystania funkcji skrótu jest fakt, że po jego przeliczeniu baza danych nie musi iterować po tabeli a od razu trafia na odpowiedni rekord w tabeli skrótów (hash table lub build table).”
Tego trochę nie rozumiem, baza po prostu zamiast sprawdzać po wartości kolumny sprawdza po hashu. Dlaczego sprawdzanie po hashu jest szybsze ? Nie widzę “wartości dodanej” sprawdzania po hashu :/, możliwe że jest to ukryte pod własnościami funkcji hash, a których nie znam dogłębnie.
Rozważmy taki przykład wraz z pesudokodem:
Mamy standardową tablicę z 100 elementami.
Dostanie się do elementu 40 tej listy można zrealizować na dwa sposoby
1. tab[40] <-- pobranie elementu z tablicy w taki sposób wymaga około jednej operacjii 2. for i in 100 if tab[i] == warunek then return <-- tu iterujemy po kolei po tablicy, przybliżony koszt to 40 Oczywiście pierwsza opcja jest znacznie szybsza. Ale co w momencie gdy mamy tablicę z nazwami miast a chcemy znaleźć w tablicy konkretną nazwę? Teoretycznie możliwa jest tylko opcja nr 2 czyli przeliterowanie po elementach tablicy aż znajdziemy ten z interesującą nas nazwą. A teraz gdybyśmy do każdej nazwy przypisali index z tablicy? Wtedy moglibyśmy z tablicy pobrać element w taki sam sposób jak w opcji nr. 1 Odpowiadając na pytanie gdzie tu wartość dodana. Dla wyszukania jeden wartości nie opłaca się tworzyć tablicy hashy ale gdy jest ich więcej staje się to opłacalne ponieważ wyszukujemy elementy bardzo małym kosztem. Dodatkowo polecam przeczytać opis na wikipedii: https://pl.wikipedia.org/wiki/Tablica_mieszająca
Dzięki, pominąłem fakt, że tablica skrótów jest posortowana po hashu :).