
SQL Code Review jest w wielu zespołach czynnością obowiązkową w trakcie wytwarzania oprogramowania. Ale czy zawsze programiści przykładają dużą wagę do code review SQL? Moje doświadczenia i odczucia pokazują, że code review SQL jest traktowane dość po macoszemu a szczególnie tam gdzie SQL nie jest głównym językiem. Gdy tworzymy aplikację z użyciem JAVA, C#, Pythona czy innego języka sprawdzenie jak napisany został kod SQL często jest odkładane na dalszy plan.
Ten kurs jest częścią cyklu Kurs SQL
Zapisz się na autorskie Szkolenie SQL
W kursie tym opiszę jakie stosuję praktyki i zasady przy wykonywaniu cod review SQL. Kurs ten będę rozbudowywał z czasem o nowe punkty oraz uzupełniał o linki do kursów które uzasadnią pewne podejście. Część zasad wynikać będzie z dobrych praktyk gdzie pokażę błędy oraz ich konsekwencje a część będzie moimi osobistymi zasadami które ułatwiają mi pracę.
Warto w czasie Code Review SQL zwrócić uwagę na formatowanie kodu i standardy jakich stosujemy. W tym kursie nie opiszę zasad formatowania ponieważ każda osoba, zespół czy firma ma swoje. Jeżeli chcesz zobaczyć jaki ja preferuję zobacz wpis Formatowanie kodu SQL
Zapytania
Miejscem gdzie znaleźć można bardzo wiele miejsc do poprawy a jednocześnie miejsce gdzie można znaleźć wiele ważnych błędów są zapytania SELECT.
Używanie * w SELECT
Zacznę od chyba najpopularniejszego błąd szczególnie w przypadku wykorzystania niewielu tabel. Przejdźmy od razu do przykładu:
SELECT
*
FROM FOO F
JOIN BAR B ON B.FOO_ID = F.ID
WHERE 1 = 1
AND F.KOLUMNA = '111';Z pozoru zapytanie jak wiele. Jednak w * (gwiazdce) kryje się wiele zła. Jeżeli na tabeli FOO lub BAR występują indeksy to możliwe, że ich potencjał zostanie częściowo zniwelowany poprzez użycie *. Dzieje się tak dlatego, że baza może wykorzystać indeksy i pobrać z nich część danych jednak powyższe zapytanie wymusza na bazie danych pobranie danych z wszystkich kolumn tabeli. Wystarczy więc, że jednej kolumny nie ma w wykorzystywanym indeksie żeby baza za każdym razem musiała sięgać do tabeli. Jeżeli w zapytaniu wypiszemy konkretne kolumny to możliwe, że baza wykona zapytanie nie sięgając w ogóle do danych w tabeli a wykorzysta jedynie indeksy. Dokładny opis tego mechanizmu opisałem w kursie SQL: Table Acess By Index ROWID
Zwrócić uwagę na kolejność w warunkach WHERE
W kursie Kolejność warunków w WHERE opisuję, że w bazie danych Oracle znaczenie ma kolejność wykonania warunków w klauzuli WHERE. Warto wziąć pod uwagę, że baza danych Oracle przy przetwarzaniu zapytania korzysta z minimalnej ewaluacji czyli jeżeli kolejne warunki nie zmienią wyniku wyrażenia booleanowskiego baza ich nie wykona.
Pisząc warunek WHERE warto brać pod uwagę kolejności w jakiej baza danych wykona ograniczenia. Szczególnie ważne jest wykorzystanie podzapytań. Jeżeli wiemy, że podzapytanie zwróci tylko jedną wartość może lepiej wyciągnąć ją wcześniej i w warunku WHERE wykorzystywać już samą wartość. Natomiast używając funkcji w WHERE warto znać ich pracochłonność, zwrócić uwagę czy nie uniemożliwiają wykorzystanie indeksu czy aby na pewno nie da się napisać zapytania bez ich użycia.
LEFT JOIN z warunkiem w WHERE
Zasada ta dotycząca Code Review łączenia tabeli przy pomocy LEFT JOIN oraz wykorzystania kolumny z tabeli łączonej w warunku where jak na poniższym przykładzie:
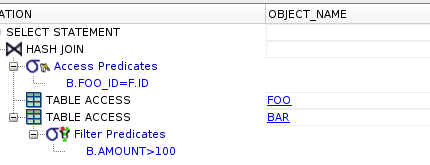
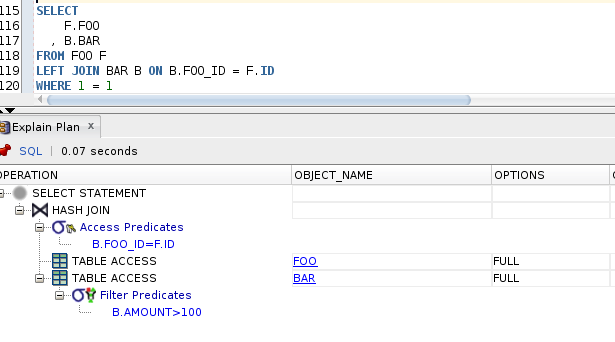
SELECT
F.FOO
, B.BAR
FROM FOO F
LEFT JOIN BAR B ON B.FOO_ID = F.ID
WHERE 1 = 1
AND B.AMOUNT >= 100;Oraz niewielki zestaw danych:
FOO BAR ID|FOO FOO_ID|BAR|AMOUNT 1 |'XX' 1 |'X'|100 2 |'YY' 2 |'Y'|10 3 |'ZZ'
Jaki wynik zwróci powyższe zapytanie dla powyższych danych i jakie były intencje autora? Patrząc na to zapytanie teoretycznie baza w pierwszej kolejności dołączy przy pomocy LEFT JOIN do tabeli FOO rekordy z tabeli BAR a następnie wykona filtrowanie po kolumnie AMOUNT. Finalnie dla powyższego zapytania otrzymamy jeden rekord. Czy taka była intencja autora? A może autor chciał użyć LEFT JOIN z tabeli BAR ale tylko rekordów spełniających warunek AMOUNT>=100? Nie jest to pewnie. Co jednak najważniejsze baza wcale nie wykona LEFT JOIN a zwykłego JOIN. W związku z tym nie ma sensu pisać “LEFT” bo zamazuje to intencje autora:
JOIN do tabeli z LEFT JOIN
Będąc przy LEFT JOIN rozpatrzmy inny częsty przykład który warto wychwycić i poprawić w SQL aby był bardziej czytelny. Załóżmy sytuację gdy łączymy trzy tabele jak w poniższym zapytaniu:
SELECT
F.FOO
, B.BAR
FROM FOO F
LEFT JOIN BAR B ON B.FOO_ID = F.ID
JOIN FOOBAR FB ON FB.BAR_ID = B.ID
WHERE 1 = 1;Przy przeglądaniu powyższego zapytania znów można zadać pytanie jaka była intencja autora? Czy chciał do tabeli FOO dołączyć tylko tabele BAR które mają połączenie z tabelą FOOBAR? Czy może chciał uzyskać inny wynik? Baza natomiast podobnie jak powyżej wykona JOIN do tabeli BAR zamiast LEFT JOIN jak na poniższym planie:
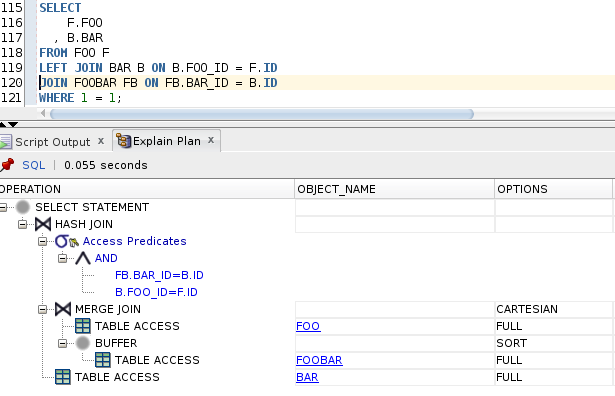
W związku z tym, że baza wykona JOIN zamiast LEFT JOIN poprawmy takie zapytanie na JOIN BAR… aby było czytelniej i dokładnie znana była intencja autora kodu.
Przyrównanie do NULL
Przyrównanie do wartości NULL oraz wprowadzenie w SQL logiki trójwartościowej powoduje wiele na pierwszy rzut oka nieoczywistych zachowań bazy danych. Warto w trakcie code review szczególną uwagę na przyrównania do null. Rozważmy poniższy przykład z prostą tabelą i kilkoma rekordami:
CREATE TABLE FOO_TAB (
ID NUMBER NOT NULL
, FOO_COL VARCHAR2(10 CHAR)
);
INSERT INTO FOO_TAB(ID, FOO_COL) VALUES (1, 'FOO');
INSERT INTO FOO_TAB(ID, FOO_COL) VALUES (2, NULL);
INSERT INTO FOO_TAB(ID, FOO_COL) VALUES (3, 'BAR');
COMMIT;Wykonajmy na powyższej tabeli zapytanie:
SELECT
ID
, FOO_COL
FROM FOO_TAB
WHERE 1=1
AND FOO_COL = NULL;Na pierwszy rzut oka warunek w WHERE wydaje się logiczny ale niestety. Przyrównanie do NULL zawsze zwraca ani True ani False a NULL. A co zwraca null=null, a no zwraca null 🙂 Dlatego jeżeli widzisz przyrównanie do wartości NULL lub widzisz przyrównanie do kolumny która może zawierać null dokonaj chwilowej refleksji czy aby na pewno jest to poprawne.
Tworzenie struktury bazy danych
Tworzenie struktury bazy danych czyli tabele, indeksy czy powiązania między nimi.
NOT NULL jako ostatnia kolumna
Temat dotyczy budowania tabeli. Umiejscowienie kolumn z dopuszczalną wartością NULL i NOT NULL ma znaczenie dla jej wielkości. Wielkość tabeli ma bezpośredni wpływ na szybkość jej przetwarzania. W skróci kolumny z wartością null na końcu tabeli zajmują mniej miejsca niż tabela z kolumną not null na końcu. Nie trzeba do tego podchodzić bardzo rygorystycznie ale jeżeli istnieje taka możliwość przenieśmy kolumny not null na początek tabeli. Jeżeli więc widzimy poniższą tabelę:
CREATE TABLE FOO (
COL1 VARCHAR2(255)
, COL2 VARCHAR2(255)
, COL3 VARCHAR2(255)
, COL4 VARCHAR2(255)
, COL5 VARCHAR2(255)
, COL6 VARCHAR2(255)
, COL7 VARCHAR2(255)
, COL8 VARCHAR2(255)
, COL9 VARCHAR2(255)
, COL10 VARCHAR2(255) NOT NULL
);Zamieńmy kolejność jej kolumn tak aby kolumna/y not null były na początku np.:
CREATE TABLE FOO (
COL10 VARCHAR2(255) NOT NULL
, COL1 VARCHAR2(255)
, COL2 VARCHAR2(255)
, COL3 VARCHAR2(255)
, COL4 VARCHAR2(255)
, COL5 VARCHAR2(255)
, COL6 VARCHAR2(255)
, COL7 VARCHAR2(255)
, COL8 VARCHAR2(255)
, COL9 VARCHAR2(255)
);Dokładny opis powyższego mechanizmu oraz wpływ kolejności kolumn null/not null opisałem w kursie kolejność kolumn w tabelii.
DEFAULT na kolumnach z NOT NULL i bez NOT NULL
Jeżeli widzimy wprowadzenie, że ktoś chce dodać nową kolumnę typu NOT NULL i jednocześnie aktualizuje wszystkie rekordy to powinna zapalić nam się czerwona lampka. Mianowicie w Oracle od wersji 11g istnieje specjalny mechanizm wktóry w przypadku dodania kolumny NOT NULL z zadeklarowaną wartością DEFAULT nie zmienia fizycznie struktury tabeli tzn. nie aktualizuje rekordów o wartość DEFAULT a trzyma ją z boku i w momencie pobierania danych z tabeli podmienia wartość pustą na tą z DEFAULT. Znaczenie tego mechanizmu jest takie, że dodanie takiej kolumny jest bardzo szybkie bo nie trzeba aktualizować wszystkich rekordów oraz rozmiar samej tabeli jest mniejszy a co za tym idzie szybciej możemy ją przeszukiwać. Dokładny opis powyższego mechanizmu opisałem w kursie: DEFAULT na kolumnach NULL i NOT NULL
Oddzielenie DDL od INSERTÓW
W mojej opinii warto oddzielać pliki służące do utworzenia struktury bazy danych w tym np. tabel od wartości które ładujemy do tych tabel. Jest to wartościowe ponieważ po wykonaniu DDL w bazie Oracle następuje automatycznie commit co może nie zawsze być porządane czy widoczne. Kolejną zaletą z oddzielenia struktury od samych wartości jest fakt, że powiązania między tabelami mają wpływ które dane możemy załadować a które nie. Rozwiązanie takie jest po prostu czystsze.
Rozważmy poniższy skrypt:
CREATE TABLE BAR (
CODE VARCHAR2(3 CHAR)
, NAZWA VARCHAR2(30 CHAR)
, CONSTRAINT CODE_PK PRIMARY KEY (CODE)
);
INSERT INTO BAR(CODE, NAZWA) VALUES ('PL', 'POLSKA');
INSERT INTO BAR(CODE, NAZWA) VALUES ('DE', 'NIEMCY');
CREATE TABLE FOO (
IMIE VARCHAR2(100 CHAR)
, BAR_CODE VARCHAR2(3 CHAR)
, CONSTRAINT FOO_BAR_FK FOREIGN KEY (BAR_CODE) REFERENCES BAR(CODE)
);
INSERT INTO FOO(IMIE, BAR_CODE) VALUES ('JAN', 'PL');
INSERT INTO FOO(IMIE, BAR_CODE) VALUES ('ADAM', 'PL');
INSERT INTO FOO(IMIE, BAR_CODE) VALUES ('EDMUNT', 'DE');Powyżej widzimy ładny skrypt, utworzone dwie tabele, załadowane jakieś dane inicjalne. skrypt nie zwraca błędów. Ale czy na pewno jest OK? Czy ostatnie trzy rekordy zostały załadowane i zacommitowane? Pewnie to zależy czy skrypt uruchomimy jakimś narzędziem czy sami go uruchomimy. Czy na końcu zawsze będziemy pamiętać aby dodać commit? Może w ramach sprawdzenia otworzymy inną sesje i sprawdzimy tylko tabelę BAR w której dane są zacommitowane, a czy sprawdzimy tabelę FOO? Generalnie te pytania powodują, że dla czystości lepiej oddzielać pliki z strukturą danych oraz pliki z danymi którymi chcemy załadować tą strukturę.
Przy okazji dawania kodu DML warto na końcu dodać COMMIT co by jasno go zaznaczyć 🙂
Dwie tabele powiązane kluczem z różnymi wartościami w kolumnach
W sytuacji gdy mamy dwie tabele z kolumnami które są powiązane relacją i każda z nich ma inny typ jest sytuacją z zasady błędną. Zobaczmy poniższy skrypt:
CREATE TABLE BAR (
CODE VARCHAR2(2 CHAR)
, NAZWA VARCHAR2(30 CHAR)
, CONSTRAINT CODE_PK PRIMARY KEY (CODE)
);
CREATE TABLE FOO (
IMIE VARCHAR2(100 CHAR)
, BAR_CODE VARCHAR2(3 CHAR)
, CONSTRAINT FOO_BAR_FK FOREIGN KEY (BAR_CODE) REFERENCES BAR(CODE)
);Powyższy skrypt nie wyrzuca błędu natomiast kolumna CODE w tabeli BAR jest wielkości 2char natomiast kolumna referująca BAR_CODE z tabeli FOO jest wielkości 3char. CONSTRAINT został utworzony ponieważ sama taka forma nie jest błędem natomiast co stanie się gdy będziemy chcieli dodać do tabeli FOO rekord z BAR_CODE długości 3 znaków? Zawsze będzie błędny i nie będzie możliwości utworzenia rekordu w tabeli BAR z taką wartością.
Kolumna typu VARCHAR2() bez podania typu danych
Szczególną uwagę należy zwrócić na kolumny typu varchar2 bez podanego typu jaki obsługuje. Mianowicie domyślnie długość w kolumnie varchar2 ustawiana jest na długość bajta i nie jest to błędem. Warto jednak pamiętać, że polskie litery zajmują 2 bajty i w kolumnie VARCHAR2(4) nie zmieści się słowo “król”. Dlatego proponuję aby zawsze podawać typ danych przy kolumnie varchar2 z szczególnym zaznaczeniem czy w naszym kreuje nie powinna to być w większości wartość char? Zobaczmy poniższy przykład:
CREATE TABLE FOO (
FOO VARCHAR2(4)
, BAR VARCHAR2(4 CHAR)
);
INSERT INTO FOO(FOO, BAR) VALUES ('KRÓL', 'KRÓL');oraz zwrócony błąd:
INSERT INTO FOO(FOO, BAR) VALUES ('KRÓL', 'KRÓL')
Error report -
ORA-12899: value too large for column "SYSTEM"."FOO"."FOO" (actual: 5, maximum: 4)Na pierwszy rzut oka nie widać różnic między kolumnami i dopiero probe dodania zbyt długiego ciągu powoduje błąd.
Podsumowanie
Warto robić Code Review kodu SQL który piszemy i który piszą inni. Jest to moment gdzie można znaleźć naprawdę wiele błędów samego kodu jak i wymagań. Inna osoba spraszająca kod może wnieść niesamowitą wartość w kod który piszemy, nieraz okaże się, coś można zrobić łatwiej lepiej albo po prostu inaczej. Kurs ten będę z czasem rozszerzał o kolejne elementy.
Ja gdy robię Code Review SQL zwracam uwagę na:
- Formatowanie, ważne żeby zgodne z naszymi standardami
- Stosowanie * przy zapytaniach SELECT
- Przyglądam się kolejności w warunkach WHERE
- Sprawdzam, czy nie ma w warunku WHERE wykorzystanych kolumn z “LEFT JOIN”
- Szukam, czy nie ma JOIN do tabeli która wcześniej jest “LEFT JOIN”
- Jeśli widzę przyrównanie do NULL to zastanawiam się czy aby na pewno jest poprawne
- Przy tworzeniu tabel patrzę czy kolumny not null są na początku
- Jak widzę DEFAULT na kolumnie z dopuszczalną wartością NULL to zastanawiam się czy na pewno ta kolumna powinna dopuszczać NULL
- Zwracam uwagę na oddzielenie INSERTów od DDLi
- Zwracam uwagę czy CONSTRAINTy są na kolumnach o tym samym typie i wielkości
- Pilnuję aby VARCHAR2 podawany był z typem np. char
Bardzo fajne przykłady, jednak mam pytanie dlaczego u mnie przykład z “KRÓL” może nie wyrzucać błędu?
Twoje pytanie właściwie potwierdza dlaczego uważam, że powinno się podawać typ w kolumnie. Aby uniknąć podobnych problemów z domysłami jaki typ podstawi się pod VARCHAR. Dodanie CHAR lub BYTE powoduje, że mamy pewność jakiego typu będzie długość kolumny 🙂
Przykład z królem nie zwraca błędu ponieważ najprawdopodobniej twoja kolumna jest typu char.
Wykonaj operację DESC na tabeli i zobacz jakiego typu masz kolumnę.
Dodatkowo zobacz jak masz ustawiony parametr “nls_length_semantics”. Parametr ten mówi jaki typ masz jako domyślny w varcharach. Jeżeli masz wartość CHAR to znaczy, że nie podając typu w VARCHAR zawsze podstawi domyślnie CHAR. U mnie ten parametr ma wartość BYTE dlatego nie podając typu wchodzi u mnie BYTE i przykład z “królem” zwraca błąd 🙂
Parametr ten możesz sprawdzić przy pomocy poniższego zapytania:
SELECT
name,
value
FROM
v$parameter
WHERE
name = ‘nls_length_semantics’;
Cześć, nie mogę sobie ułożyć w głowie jak chcesz zrealizować to zadanie:
“Jeżeli wiemy, że podzapytanie zwróci tylko jedną wartość może lepiej wyciągnąć ją wcześniej i w warunku WHERE wykorzystywać już samą wartość.”
Czy myślisz o wyciągnięciu podzapytania do innej tabeli, czy o zrealizowaniu tego w jednym zapytaniu 🙂 ?
Super kurs, pozdrowaniam
Raczej chodzi mi o wykonanie podzapytanie w pierwszej kolejności np. chwilę wcześniej i przeklejenie wyniku tego podzapytania. Ewentualnie zapewnienie, że takie podzapytanie zostanie wykonane w pierwszej kolejności, a zrealizować można to na wiele sposobów.
Przykład z LEFT JOIN z warunkiem w WHERE zwróci zero rekordów, a nie jeden.
Faktycznie, poprawione tak, że zwróci jeden rekord 🙂