
W tym kursie Oracle SQL opiszę zupełnie inny od wszystkich sposób odczytu indexu. Skanowanie Index Fast Full Scan jest szczególnym skanowaniem indexu ze względu na sposób działania ponieważ jest niezależnym od struktury indexu. Index Fast Full Scan jest odpowiednikiem Full Scan na tabeli.
Ten wpis jest częścią Kurs Oracle SQL
W poprzednim kursie Oracle SQL dotyczącym Index Full Scan opisywałem jak realizowana jest potrzeba odczytu pełnego indexu w posortowanej kolejności.
Fast Full Index Scan jest skanowaniem w samym indeksie bez dostępu do tabeli, baza danych odczytuje bloki indeksu bez określonej kolejności. Aby baza wykorzystała Fast Full Scan muszą zostać spełnione następujące warunki:
- Indeks musi zawierać wszystkie kolumny potrzebne do zapytania.
- W zapytaniu nie może wystąpić sortowanie
- Zapytanie musi zapewnić, że nie pojawią się wyniki nullowe poprzez:
- Wykorzystanie kolumny NOT NULL
- Ograniczenie np. WHERE column_name IS NOT NULL
Działanie Fast Full Index Scan
Tak jak wspomniałem na początku działanie Fast Full Scan jest szczególnym skanowaniem ze względu na sposób działania i jest zupełnie różnym skanowaniem od pozostałych skanowań indeksów. Skanowanie to w ogólne nie wykorzystuje logicznej budowy indeksu takiej jaką znamy np. z kursu Index w Oracle. Fast Full Index Scan pobiera bloki indeksu tak jak są rozmieszczone fizycznie na dysku. Czyta każdy blok indexu: blok wejścia do indeksu, bloki gałęzi oraz bloki danych w takiej kolejności jakiej znajdują się fizycznie na dysku. Następnie ignoruje blok wejścia oraz bloki gałęzi i w wyniku prezentuje tylko bloki danych. Jako, że baza danych czyta bloki po kolei w takiej kolejności jak są rozmieszczone fizycznie nie jest w stanie ich przedstawić posortowanych. Posortowanie danych w tym przypadku wymaga dodatkowej operacji sortowania (choć wtedy baza najpewniej wybierze Full Scan indexu).
Index Fast Full Scan jest bardzo szybkim skanowaniem indexu w sytuacji gdy pobieramy dane z dużej części lub całego indeksu. Dzieje się tak, ponieważ baza danych Oracle w tej metodzie skanowania wykorzystuje mechanizm “multiblock read I/O” który pozwala aby przy użyciu jednej operacji I/O odczytać wiele bloków danych. Przy użyciu tego mechanizmu baza wczytuje wiele kolejnych bloków danych zgodnie z ich kolejnością na dysku. Z tego powodu w Fast Full Index Scan dane które są prezentowane nie są posortowane.
Uproszczona idea porównania modelu logicznego indexu oraz odczytu danych z dysku została przedstawiona poniżej.
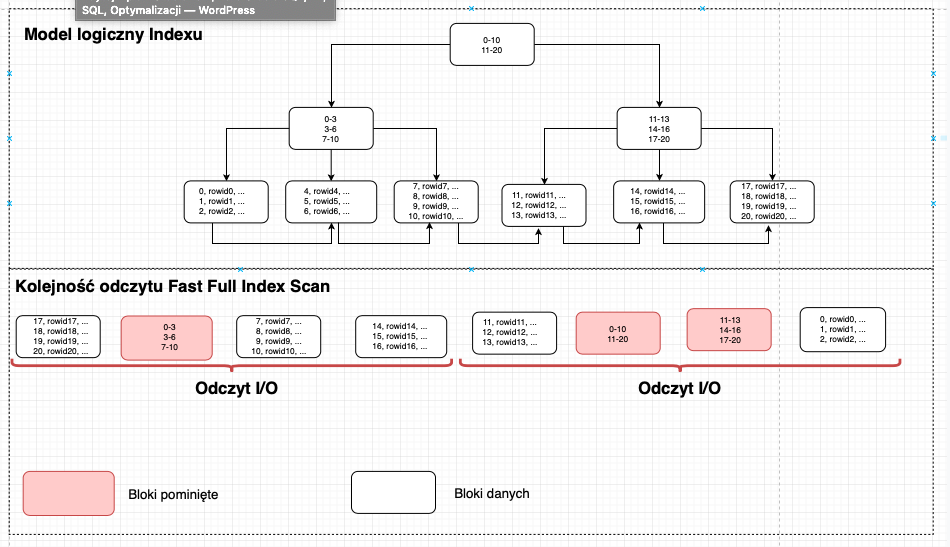
Powyższy schemat jest sporym uproszczeniem. Należy pamiętać, że blok danych jest zupełnie inną strukturą niż blok w indeksie (jeden blok indexu może zawierać wiele bloków danych) jednak dla pokazania ideii zostały one zrównane. Rozmieszczenie danych fizycznie na dysku w bazie (bloki, extendy, segmenty itp.) przedstawię w innym kursie.
Dane testowe
Skoro wiemy kiedy i jak działa omawiana metoda skanowania to przeprowadźmy kilka testów działania tego indexu. W pierwszej kolejności przygotujmy tabelę:
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO VARCHAR2(255)
, BAR NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);Z 1 000 000 rekordów:
BEGIN
FOR I IN 0 .. 1000000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
, FIS
) VALUES (
'ACME: ' || MOD(I, 10)
, MOD(I, 10000)
, DECODE(MOD(I, 1000), 1, I, NULL)
);
END LOOP;
END;
/
COMMIT;Oraz przeliczmy statystyki tabeli:
EXEC DBMS_STATS.GATHER_TABLE_STATS('SYSTEM','TEST_TABLE');Po wykonaniu powyższych poleceń przygotowaliśmy środowisko gotowe do testów.
Utwórzmy więc index na kolumnie BAR:
CREATE INDEX TEST_TABLE_BAR_IDX ON TEST_TABLE(BAR);Index Fast Full Scan
Posiadając środowisko testowe możemy przystąpić do testów. Rozpocznijmy od najprostszego przypadku gdy pobieramy wszystkie dane z jednej kolumny bez ograniczeń:
SELECT
BAR
FROM TEST_TABLE;Oraz plan:

Na planie zapytania widzimy wykorzystanie metody Full Scan na tabeli. Dzieje się tak ponieważ nie dodaliśmy ograniczenia na kolumnę BAR a w indexie znajdują się wartości nie nullowe dlatego też baza żeby pobrać wszystkie dane musi pobrać je z tabeli a nie z indexu.
Zmodyfikujmy więc zapytanie dodając ograniczenie na kolumnę BAR IS NOT NULL:
SELECT
BAR
FROM TEST_TABLE
WHERE BAR IS NOT NULL;Oraz plan:

Na powyższym planie widzimy wykorzystanie metody FAST FULL SCAN na utworzonym indexie TEST_TABLE_BAR_IDX. Wzorowe wręcz skanowanie, pobieramy dane z całego indexu, baza skanuje blok po bloku i prezentuje nam dane.
Co się, natomiast stanie gdy bardziej ograniczymy wynik zapytania:
SELECT
BAR
FROM TEST_TABLE
WHERE BAR < 10000;Oraz plan:

Na powyższym planie widzimy wykorzystanie Range Scan nie natomiast Fast Full Scan. Dzieje się tak, ponieważ wybraliśmy niewielką ilość rekordów z indexu i baza wyliczyła, że szybciej będzie przeskanować index metodą Range Scan niż skanować cały index. Baza wybierze Range Scan w sytuacji gdy pobierać będziemy do ok 10-20% rekordów z indexu, jeżeli pobierzemy więcej danych wtedy baza użyje metody Fast Full Scan.
Baza danych wybierze również Fast Full Scan w momencie wyszukania COUNT(*) z tabeli:
SELECT
COUNT(*)
FROM TEST_TABLE;Oraz plan:

Jak widzimy, po powyższym planie baza wykorzystała metodę Fast Full Scan indexu ID_PK do przeliczenia ilości rekordów w tabeli.
Zgodnie z definicją Fast Full Scan nie zadziała gdy będziemy sortować wynik, zobaczmy więc:
SELECT
BAR
FROM TEST_TABLE
WHERE BAR IS NOT NULL
ORDER BY BAR;Oraz plan:

Zgodnie z definicją baza wykorzysta Full Scan do wyszukania danych, nie wykorzysta natomiast Fast Full Scan. Jest to zrozumiałe ponieważ przy skanowaniu Fast Full Scan baza musiałaby dodatkowo posortować dane co jest znacznie bardziej kosztowne niż wykorzystanie posortowanego indexu i wykorzystanie metody Full Scan. Dokładny opis działania Full Scan opisałem w kursie SQL: Index Full Scan
Podsumowanie
- Fast Full Scan odczytuje dane w kolejności w jakiej znajdują się na dysku
- W tej metodzie skanowania wykorzystywany jest mechanizm odczytu wielu bloków przy wykorzystaniu jednej operacji I/O
- Dodanie klauzuli ORDER BY uniemożliwi skorzystanie z Fast Full Index Scan
- Gdy z tabeli pobierzemy do ok. 10-20% rekordów to baza wybierze raczej Range Scan