
W poprzednim kursie dotyczącym INDEX UNIQUE SCAN opisywałem potrzebę wyszukania jednego rekordu przy użyciu unikalnego klucza. Często zachodzi jednak potrzeba przeszukania tabeli i znalezienia w niej wielu rekordów obwarowanych różnymi warunkami.
Ten wpis jest częścią Kurs Oracle SQL
INDEX RANGE SCAN to uporządkowane skanowanie indeksu, w którym co najmniej jedna kolumna wiodąca indeksu jest określona w warunkach WHERE. Zakres skanowania klucza może być ograniczony z obu stron lub bez ograniczeń po jednej lub obu stronach.
Aby optymalizator wybrał INDEX RANGE SCAN muszą zostać spełnione warunki:
- Skanowanie musi mieć możliwość znalezienia jednego lub wielu wartości klucza.
- W klauzuli WHERE muszą wystąpić warunki wraz z kombinacją AND:
- >
- <
- =
- Instrukcja LIKE ale tylko w przypadku gdy początek jest ściśle określony natomiast znak dopełnienia ( _%) występuje na końcu np. WHERE NAME LIKE TEST%
Działanie INDEX RANGE SCAN
INDEX RANGE SCAN rozpoczyna przeszukanie indexu od bloku korzenia (root block) i dalej skanuje kolejne bloki gałęzi aż znajdzie pierwszy blok liścia. Pierwszym blokiem liścia zidentyfikowanym przez index będzie blok w którym wartości są najmniejsze spośród poszukiwanych.
Następnie przeszukiwany jest blok liścia po kolei wyszukując kluczy spełniających warunki ograniczenia. Po przeszukaniu bloku liścia następuje przejściu na kolejny blok liścia aż do momentu zakończenia indexu lub spełnieniu ostatniego warunku.
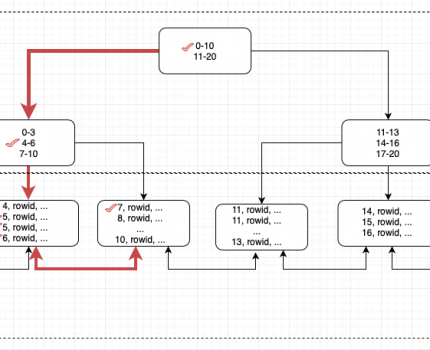
Przeszukując index z kluczami w zakresie od 5 do 7 RANGE SCAN indexu wygląda następująco:
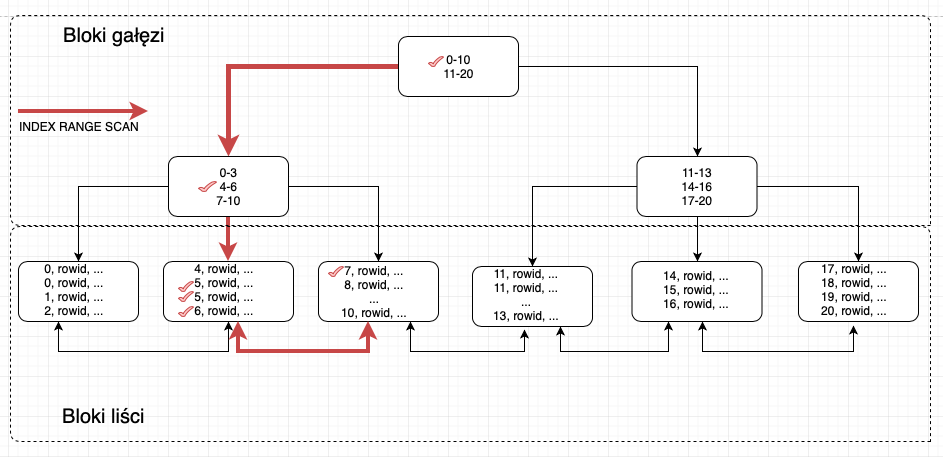
Na powyższym diagramie przedstawiona została ścieżka przeszukania indexu metodą RANGE SCAN. Dzięki przeszukaniu indexu wystarczyło sprawdzić jedynie bloki gałęzi i bloki liści w których mogą znajdować się dane spełniające warunki z klauzuli WHERE. Zdecydowana większość danych niespełniających warunków nie została bezpośrednio przeskanowana. Metoda ta pozwala na znacznie przyspieszenie znalezienia selektywnych danych.
Przykłady użycia INDEX RANGE SCAN
Przygotowanie danych
Tak jak w poprzednim wpisie dotyczącym INDEX UNIQUE SCAN tak i w tym użyjemy tabeli TEST_TABLE która zawiera unikalne ID na które nałożony jest PRIMARY KEY, jedna kolumna typu NUMBER oraz jedna typu VARCHAR2.
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO VARCHAR2(255)
, BAR NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);Do uzupełnienia tabeli danymi posłuży skrypt poniżej. Wypełni tablę TEST_TABLE 1 000 000 rekordów które mają powtarzające się wartości w kolumnie FOO i BAR:
BEGIN
FOR I IN 0 .. 1000000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
) VALUES (
'ACME: ' || MOD(I, 10)
, MOD(I, 10000)
);
END LOOP;
END;
/
COMMIT;Aby przy tworzeniu indexu nie zakłamywać przeliczmy statystyki tabeli:
EXEC DBMS_STATS.GATHER_TABLE_STATS('SYSTEM','TEST_TABLE');Po wykonaniu powyższych poleceń przygotowaliśmy środowisko gotowe do testów.
Index na kolumnie numerycznej BAR
Gdy już przygotowaliśmy środowisko możemy utworzyć pierwszy index. Na początku stworzymy index jednokolumnowy na kolumnie BAR. Kolumna BAR przyjmuje wartości numeryczne które są selektywne tzn. są powtarzalne.
CREATE INDEX TEST_TABLE_BAR_IDX ON TEST_TABLE(BAR);Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “=”
Najprostsze zapytanie wyciągające dane z z jedną wartością 50 000
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR = 500000;
Jak widzimy plan zapytania chce skorzystać z INDEXU TEST_TABLE_BAR_IDX oraz metody skanowania RANGE SCAN. Zapytanie skorzystało z tego typu skanowania ponieważ zostały spełnione wszystkie warunki czyli w tabeli znajdują się dane selektywne, oraz wykorzystaliśmy jeden z warunków (w tym przypadku “=”).
Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “>” i “<“
Zgodnie z opisem warunków range scane obsługuje również ograniczenia “>” oraz “<” tak więc przykład poniższe zapytanie:
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR > 10000;I plan zapytania:

Jak widzimy optymalizator zamierza wykorzystać INDEX RANGE SCAN i nie jest to zaskoczeniem. Nasuwa się pytanie czy w sytuacji gdy ograniczymy wyniki zapytania “>” lub “<” optymalizator zawsze wybierze RANGE SCAN po indexie? Zobaczmy więc co się stanie gdy zmienimy ograniczenie > na wartości z 10 000 na 1.
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR > 1;
Na powyższym planie optymalizator wybrał FAST FULL SCAN po indexie zamiast RANGE SCAN. Dzieje się tak dlatego, że przeszukanie wszystkich wartości z indexu po kolei jest szybsze niż szukanie danych po całej strukturze B drzewa ( bloki gałęzi oraz bloki danych). W skrócie aby zrozumieć co się stało należy wiedzieć, że w przypadku metody FAST FULL SCAN INDEX jest przeszukiwany po wszystkich blokach danych bez względu na bloki gałęzi. Tak więc optymalizator wybierze RANGE SCAN wtedy gdy przeszukiwanie po gałęziach indexu jest szybsze(wymaga mniej operacji) niż przeskanowanie wszystkich rekordów bloków danych (leaf block) indexu po kolei.
Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “<>”?
W przypadku ograniczenia “<>” jest niemal niemożliwe uzyskanie innego skanowania jak FAST FULL SCAN ponieważ z zasady ograniczenie to zwraca większość rekordów z pominięciem tych w warunku. Zróbmy więc test:
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR <> 10;
Widzimy, że zgodnie z przewidywaniem powyższy plan wykorzystuje FAST FULL SCAN ponieważ wyszukujemy zdecydowaną większość rekordów z indexu z pominięciem jedynie niewielkiej jej części gdzie BAR = 10.
Index na kolumnie VARCHAR2 FOO
W poniższym przykładzie wykorzystamy inny index który nałożony zostanie na kolumnie FOO która jest typu VARCHAR2(255). Dane w kolumnie FOO są powtarzalne. Istnieje jedynie 10 niepowtarzalnych wartości.
CREATE INDEX TEST_TABLE_FOO_IDX ON TEST_TABLE(FOO);Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “=”
Tak jak w przypadku kolumny numerycznej postaramy się wyszukać dane pasujące dokładnie do jednego wzorca poprzez użycie ograniczenia “=”
SELECT
FOO
FROM TEST_TABLE
WHERE 1 = 1
AND FOO = 'T';Plan zapytania dla powyższego zapytania:

Plan zapytania przedstawia wykorzystanie metody RANGE SCAN po INDEX w celu wyszukania wszystkich wartości gdzie wartość wynosi dokładnie “T”. Analogicznie do przeszukiwania po wartości numerycznej.
Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “<>”?
W przypadku ograniczenia “<>” podobnie jak w przypadku kolumny typu NUMBER ciężko jest znaleźć warunek gdzie ilość ograniczonych rekordów będzie mała. Dlatego też poniższe zapytanie zapewnie nie wykorzysta metody INDEX RANGE SCAN:
SELECT
FOO
FROM TEST_TABLE
WHERE 1 = 1
AND FOO <> 'TEST';
Zgodnie z przewidywaniami optymalizator w tym przypadku wybrał metodę FAST FULL SCAN.
Sortowanie INDEX RANGE SCAN
Wiemy, że wpisy w indeksie są posortowane w związku z tym wyciągnięcie posortowanych danych nie powoduje zwiększenia kosztu zapytania. Dla przykładu zapytanie z sortowaniem ASC:
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR > 10000
ORDER BY BAR ASC;
Widzimy, że mimo dodania ORDER BY BAR ASC w planie zapytania nie widzimy żadnego sortowania oraz wzrostu kosztu. Dzieje się tak, z tego powodu, że dane w indeksie są posortowane więc kolejno znajdywane rekordy są już posortowane.
Nieco inna sytuacja stanie się, gdy odwrócimy sortowanie z ASC na DESC
SELECT
BAR
FROM TEST_TABLE
WHERE 1 = 1
AND BAR > 10000
ORDER BY BAR DESC;
W powyższym planie pojawiła się opcja RANGE SCAN DESCENDING. Skoro dane w indeksie są posortowane w kolejności “ASC” to odwrócenie pobierania danych nie jest problemem. Wystarczy czytać dane od końca.
Dlatego też koszt zapytania jest taki sam dla sortowania “ASC” jak i “DESC”
Wykorzystanie INDEX RANGE SCAN w przypadku ograniczenia “LIKE”
Na kolumnie typu NUMBER ograniczenie typu “>” lub/i “<” jest całkowicie normalnym ograniczeniem. Ciężko znaleźć potrzebę wykorzystania tego ograniczenia na kolumnie typu VARCHAR2. Jednak typowym ograniczeniem dla kolumn tekstowych jest ograniczenie LIKE w różnych wariantach. Pierwszym przykładem będzie wykorzystanie LIKE w najbardziej naiwnej postaci czyli z “%” po oby stronach. Przykładowe zapytanie:
SELECT
FOO
FROM TEST_TABLE
WHERE 1 = 1
AND FOO LIKE '%TEST%';Oraz plan zapytania:

Powyższy plan wykorzystuje FAST FULL SCAN. W kursie dotyczącym budowy indexu zaznaczyłem, że w bloku gałęzi klucz indexu trzyma pierwsze niezbędne wartości z kolumny danych. W przypadku gdy użyjemy klauzuli LIKE z znakiem dopełnienia “%” jako prefix, index nie ma możliwości przeszukiwania indexu po gałęziach ponieważ nie zna minimalnego początku tych wartości.
Zgodnie z powyższym sprawdźmy co się stanie gdy początek ograniczenia w LIKE pozostawimy stały natomiast dopełnimy końcówkę tak jak w zapytaniu LIKE z “%” na jako sufixem:
SELECT
FOO
FROM TEST_TABLE
WHERE 1 = 1
AND FOO LIKE 'TEST%';
Na powyższym planie widzimy wykorzystanie sortowania z użyciem INDEX RANGE SCAN. Jest ono możliwe ponieważ znany jest początek ograniczenia przez co możliwe jest skanowanie indeksu po blokach gałęzi aż do bloków danych. Ciężko jest uzyskać szybkie skanowanie z użyciem ograniczenia LIKE jednak przynajmniej w ten sposób możemy je przyspieszyć. Tak więc jeżeli znamy początek szukanego tekstu podajmy go bez niepotrzebnego prefixu dopełnienia “%”
Podsumowanie
INDEX RANGE SCAN jest bardzo wszechstronnym indeksem pozwalającym szybko znaleźć pewne zakresy danych. Indekx ten pozwala na przeszukiwanie nie tylko kolumn typu NUMBER ale również innych do których można użyć ograniczeń “=”, “>”, “<” czy nawet “LIKE”. Pamiętać jednak należy, że w sytuacji gdy będziemy chcieli wybrać dużą ilość danych z indeksu optymalizator najprawdopodobniej zrezygnuje z INDEX RANGE SCAN na rzecz FAST FULL SCAN.