
Index Skip Scan został wprowadzony aby umożliwić skanowanie indeksu bez użycia kolumny wiodącej. Ten rodzaj skanowania polega na “dzieleniu” indeksu na mniejsze podindeksy i skanowaniu ich. Skip Scan został wprowadzony wraz z Oracle 9i.
Ten wpis jest częścią Kurs Oracle SQL
Aby wywołać Skip Scan Index należy:
- Założyć warunek w klauzulę WHERE na kolumnie niewiodącej.
- Kolumny poprzedzające kolumnę skanowaną indexu muszą mieć niewiele unikalnych wartości.
- W wielu źródłach można jeszcze znaleźć ograniczenie: “Skip Scan potrafi pominąć tylko pierwszą kolumnę indeksu. Wykorzystanie tylko trzeciej i kolejnej kolumny nie wywoła tego skanowania”. Jest to błędne stwierdzenie i pokażę to w sekcji z przykładami (jednak rzadko spotykane).
Działanie Skip Scan Index
Działanie Index Skip Scan polega na pominięciu pierwszej/ych kolumn indexu i skanowaniu subindexów na drugiej lub kolejnej kolumnie. Liczba różnych wartości w wiodących kolumnach indeksu określa liczbę logicznych podindeksów. Im niższa liczba unikalnych wartości, tym mniej logicznych podindeksów musi utworzyć optymalizator i tym bardziej wydajne staje się skanowanie. Skip Scan odczytuje każdy indeks logiczny osobno i „pomija” bloki indeksu, które nie spełniają warunku filtru w kolumnie wiodącej.
Zważywszy na powyższe Index Skip Scan nie jest tak szybki jak skanowanie po kolumnie wiodącej jednak jest szybsze niż skanowanie całej tabeli. Skip Scan działa na zasadzie sklejania wielu podzapytań które zgodnie z dokumentacją przypominają zapytania połączone za pomocą UNION ALL.
Przykłady działania Index Skip Scan
Tak jak we wszystkich wpisach dotyczących indexów użyję tabeli TEST_TABLE która zawiera unikalne ID na które nałożony jest PRIMARY KEY, jedną kolumnę typu NUMBER oraz jedna typu VARCHAR2.
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO VARCHAR2(255)
, BAR NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);Wypełnioną danymi:
BEGIN
FOR I IN 0 .. 1000000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
) VALUES (
'ACME: ' || MOD(I, 10)
, MOD(I, 10000)
);
END LOOP;
END;
/
COMMIT;Oraz z przeliczonymi statystykami:
EXEC DBMS_STATS.GATHER_TABLE_STATS('FOO','TEST_TABLE');Zgodnie z definicją im mniej wartości w kolumnie wiodącej tym większa szansa użycia skip scan index na kolumnie drugiej. Dlatego też utwórzmy index wielokolumnowy z kolumną wiodącą FOO ( 10 wartości unikalnych) oraz BAR (10000 wartości unikalnych):
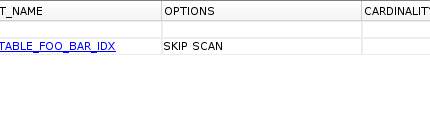
CREATE INDEX TEST_TABLE_FOO_BAR_IDX ON TEST_TABLE(FOO, BAR);Wywołajmy więc zapytanie z ograniczeniem na drugiej kolumnie BAR:
SELECT
FOO
FROM TEST_TABLE
WHERE BAR = 1000;Również zobaczmy plan

Na powyższym planie widzimy wykorzystanie Skip Scan Indexu. Pomimo pominięcia kolumny wiodącej w indexie baza wykorzystała index TEST_TABLE_FOO_BAR_IDX.
Dokumentacja Oracle podaje, że działanie Skip Scan powyżej można można przedstawić w formie zapytania:
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 0' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 1' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 2' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 3' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 4' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 5' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 6' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 7' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 8' AND BAR = 1000 UNION ALL
SELECT FOO FROM TEST_TABLE WHERE FOO = 'ACME: 9' AND BAR = 1000;Czyli w zasadzie sklejenie kilku mniejszych skanowań dla wszystkich wartości z kolumny wiodącej oraz drugiej kolumny.
Zgodnie z powyższym ilość unikalnych wartości na kolumnie powinna mieć znaczenie ponieważ większa ilość takich wartości powoduje konieczność wywołania większej ilości skanowań subindexów. Zobaczmy więc co się stanie gdy odwrócimy kolejność kolumn w indexie:
DROP INDEX TEST_TABLE_FOO_BAR_IDX;
CREATE INDEX TEST_TABLE_BAR_FOO_IDX ON TEST_TABLE(BAR, FOO);Oraz zapytanie podobne do powyższego ale z warunkiem filtrowania na kolumnę FOO:
SELECT
BAR
FROM TEST_TABLE
WHERE FOO = 'ACME: 1';oraz plan:

Jak widzimy dla analogicznego zapytania (warunek where na drugą kolumnę indexu) baza w ogóle nie wykorzystała indexu. Dzieje się tak ponieważ kolumna BAR posiada 10000 wartości unikalnych. Baza musiałaby więc wykonać ilość skanowań subindexów równą 10000 więc optymalizator uznał, że łatwiej mu będzie przeskanować całą tabelę.
Skip Scan Index na trzecią kolumnę
Zgodnie z często powtarzaną tezą, że skip scan zadziała tylko przy warunku WHERE na drugiej kolumnie przeprowadźmy test aby sprawdzić jej prawdziwość. Stwórzmy nową tabelę z 4 kolumnami gdzie będziemy mieli niewielką różnorodność wartości w kolumnach:
DROP TABLE TEST_TABLE;
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO VARCHAR2(255)
, BAR NUMBER
, COL1 NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);
BEGIN
FOR I IN 0 .. 1000000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
, COL1
) VALUES (
'ACME: ' || MOD(I, 10)
, MOD(I, 10)
, MOD(I, 100)
);
END LOOP;
END;
/
COMMIT;
EXEC DBMS_STATS.GATHER_TABLE_STATS('FOO','TEST_TABLE');Jak widzimy w powyższym skrypcie kolumna FOO i BAR posiadają po 10 unikalnych wartości a kolumna COL1 posiada ich 100.
Utwórzmy index na trzech kolumnach
CREATE INDEX TEST_TABLE_FOO_BAR_COL1_IDX ON TEST_TABLE(FOO, BAR, COL1);Zapytanie z filtrowaniem na trzeciej kolumnie indexu:
SELECT
FOO
FROM TEST_TABLE
WHERE COL1 = 2;oraz plan zapytania:

Jak widać, na powyższym planie baza danych Oracle (wersja 18c) potrafi wykorzystać Index Skip Scan na trzeciej kolumnie. Jednak aby tak się, zadziało dwie pierwsze kolumny muszą się charakteryzować niewielką unikalnością rekordów. W życiu rzadko spotykamy się z taką sytuacją, gdzie dwie pierwsze kolumny indexu posiadają mało unikalne wartości dlatego tylko czasami zobaczymy skip scan na trzeciej i kolejnej kolumnie. Niemniej jak pokazuje powyższy przykład jest to możliwe.
Podsumowanie
- Index Skip Scan pozwala wykorzystać index pomimo pominięcia kolumny wiodącej
- Aby baza Oracle wybrała Skip Scan, kolumny wiodące muszą charakteryzować się niewielką unikalnością wartości
- Możliwe jest wykorzystanie drugiej, trzeciej i kolejnej kolumny do tego typu skanowania
- Skanowanie to jest szybsze od Fast Full Scan (w odpowiednich warunkach)
Halo? Gdzie są kolejne artykuły? 😛
( oby ta długa przerwa nie oznaczała … )
Jestem na miesięcznych wakacjach dlatego nie publikuje kolejnych kursów 🙂 Więc spokojnie, za ok 2 tygodnie wrzucę kolejny kurs i wracam do regularnej publikacji 🙂
Ufff 🙂
Dzięki za info i udanego wypoczynku!
Czy mógłbyś powiedzieć w jakich konkretnych warunkach INDEX SKIP SCAN będzie szybszy od INDEX FAST FULL SCAN?
Jest błąd w INSERCIE dla pierwszego przykładu. Zbyt wiele kolumn w tabeli TEST_TABLE oraz brakuje screena z planu wykonania INDEX SKIP SCAN na trzeciej kolumnie.
INDEX FAST FULL SCAN jest szybszy w sytuacji gdy pierwsza kolumna indexu ma niewiele unikalnych wartości.
p.s. Faktycznie, poprawiłem błąd 🙂