
Index Join Scan jest łączeniem wielu indeksów, które razem zwracają wszystkie kolumny wymagane przez zapytanie. Baza danych nie musi uzyskiwać dostępu do tabeli, ponieważ wszystkie dane są pobierane tylko z indeksów.
Ten wpis jest częścią Kurs Oracle SQL
Aby wywołać Index Join Scan należy:
- W zapytaniu wykorzystać tylko kolumny będące w indexach
- Na tabeli muszą być założone przynajmniej dwa indexy
- Koszt łączenia indexów musi być mniejszy niż koszt pobrania danych z tabeli
Działanie Index Join Scan
Join Index Scan polega na skanowaniu wielu indeksów, a następnie łączeniu haszującym po ROWID uzyskanych z tych skanów, aby zwrócić wiersze wyników. Podczas tego typu skanowania zawsze unika się dostępu do tabeli. Algorytm działania skanowania:
- Przeskanuj index1 w celu wybrania odpowiadających wierszy
- Przeskanuj index2 w celu wybrania odpowiadających wierszy
- Połącz indexy po rowid
- Zwróć wynik
Dane testowe
Skoro wiemy jak działa skanowanie, przygotujmy dane testowe a więc tabelę:
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO NUMBER
, BAR NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);Uzupełnijmy ją danymi:
BEGIN
FOR I IN 0 .. 100000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
) VALUES (
DECODE(MOD(I, 1000), 1, MOD(I, 77), NULL)
, DECODE(MOD(I, 1000), 1, MOD(I, 21), NULL)
);
END LOOP;
END;
/
COMMIT;Powyższy skrypt doda 100 tyś. rekordów z czego tylko 0.1% będzie posiadać wartości w kolumnie FOO i BAR.
Przeliczmy statystyki tabeli:
EXEC DBMS_STATS.GATHER_TABLE_STATS('FOO', 'TEST_TABLE');Index Join Scan
Skoro przygotowaliśmy już dane możemy przystąpić do utworzenia dwóch prostych indexów:
CREATE INDEX TEST_TABLE_BAR_IDX ON TEST_TABLE(BAR);
CREATE INDEX TEST_TABLE_FOO_IDX ON TEST_TABLE(FOO);Utworzyliśmy dwa indexy na tabeli TEST_TABLE. Jeden na kolumnie FOO i jeden na kolumnie BAR.
Mając już te dwa indeksy możemy spróbować napisać zapytanie które wykorzysta Index Join Scan np.
SELECT
FOO
, BAR
FROM TEST_TABLE
WHERE 1 = 1
AND FOO IS NOT NULL
AND BAR IS NOT NULL;Oraz plan:

Patrząc po zapytaniu jest potencjał do wykorzystania indexów. Zapytanie wykorzystuje tylko kolumnę FOO i BAR na których są indexy. Co więcej, nałożone zostały ograniczenia IS NOT NULL dodatkowo powinno zwiększyć prawdopodobieństwo wykorzystania indexów. Niestety nie w tym przypadku. Wynika to z faktu, że koszt przeskanowania każdego z indexów oraz ich joinowania jest na tyle wysoki, że bazie łatwiej jest przeszukać całą tabelę i ją przefiltrować.
Istnieje możliwość wymuszenia wykorzystania tego typu indexu przy użyciu hinta /*+ INDEX_JOIN(TEST_TABLE)*/ dla powyższego zapytania:
SELECT /*+ INDEX_JOIN(TEST_TABLE)*/
FOO
, BAR
FROM TEST_TABLE
WHERE 1 = 1
AND FOO IS NOT NULL
AND BAR IS NOT NULL;oraz plan:

Jak widzimy, na powyższym planie zapytania zdecydowana część kosztu wynika z joinowania.
Spróbujmy więc napisać zapytanie w którym optymalizator bez naszej podpowiedzi wybierze index_join jako optymalny sposób skanowania:
SELECT
FOO
, BAR
FROM TEST_TABLE
WHERE 1 = 1
AND FOO > 1
AND BAR = 1Oraz plan zapytania:
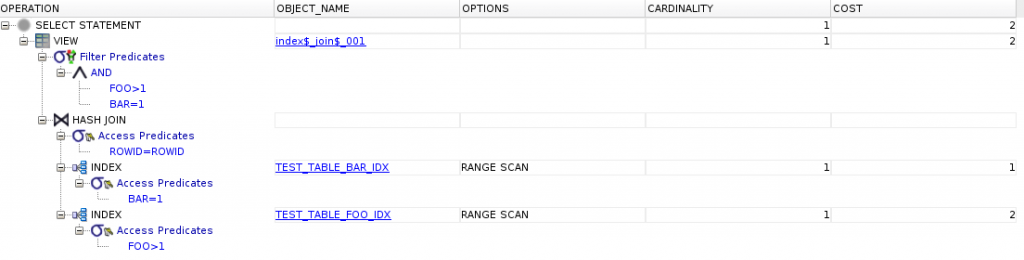
Widzimy znaczny spadek kosztu zapytania oraz wykorzystanie INDEX JOIN SCAN. W tym przypadku baza danych wykorzystała ten typ skanowania ponieważ koszt łączenia indexów był mniejszy niż koszt czytania danych z tabeli. Różne eksperymenty pokazały, że jest to kluczowy wskaźnik do użycia tego typu skanowania.
Gdy mamy index który pokrywa dużą część kolumny najczęściej wtedy baza zamiast index_join zastosuje odwołanie do tabeli. Spowodowane jest to faktem, że index przechowuje ROWID rekordu po którym baza bardzo szybko uzyskuje dostęp do rekordu w tabeli. Z tego powodu aby wykorzystać index_join potrzebujemy ograniczeń na obu indexach aby uzyskać względnie niewielką ilość rekordów.
Podsumowanie
- Koszt dostępu do indexu musi być mniejszy niż do tabeli
- Potrzebujemy ograniczeń na obu indeksach
- Aby wymusić użycie skanowania należy wykorzystać hint: INDEX_JOIN