
Często gdy posiadamy dane rozmieszczone po różnych miejscach zastanawiamy się, jak te dane ze sobą połączyć. W bazie danych dane te najczęściej rozsiane są po różnych tabelach. W łączeniu tych danych pomaga nam klauzula JOIN.
Ten wpis jest częścią Kurs Oracle SQL
Na wstępnie serii kursów po sposobach łączenia chciałbym opisać co dzieje się w bazie nim połączymy dwie tabele w jeden wynik.
Operacja JOIN często prezentowana jest tako odwrócone drzewo i tak w poniższej grafice przedstawione zostało łączenie tabeli A i B które sumarycznie dają wynik z obu tabel.
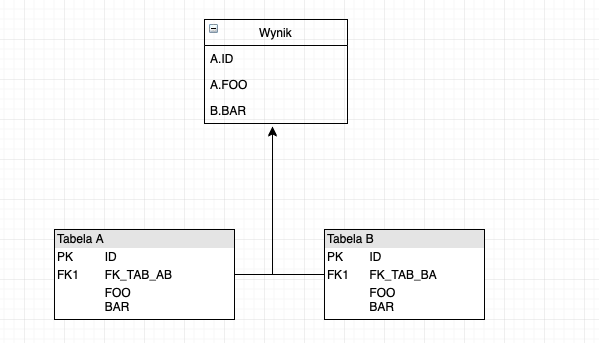
Przetwarzanie przez optymalizator operacji JOIN
W sytuacji gdy w klauzuli FROM mamy więcej niż jedną tabelę optymalizator musi zdecydować w jaki sposób optymalnie połączyć każdą z tabel. W tym celu optymalizator wykonuje kilka czynności dla określenia najlepszego sposobu połączenia:
- Kolejność łączenia – Zapytanie które łączy więcej niż dwie tabele, wymaga poukładania kolejnych łączeń. Baza danych Oracle łączy dwie tabele, a następnie dołącza wynik do następnej tabeli. Proces ten trwa, dopóki wszystkie tabele nie zostaną połączone.
- Ścieżka dostępu “access path” – W tym punkcie optymalizator decyduje o najlepszej ścieżce dostępu do danych. Wybiera czy dane pobrane zostaną z tabeli, indexu czy z innego miejsca oraz w jaki sposób. Optymalizator może w tym przypadku wybrać np. Fast Full Scan w celu najszybszego załadowania danych z tabeli/indexu lub innej struktury.
- Metoda łączenia “Join method” – W tej części optymalizator decyduje w jaki sposób połączyć tabele. Optymalizator ma do wyboru trzy typy łączenia. O tym które z nich i kiedy wybierze będę opisywał w kolejnych kursach.
- Typ złączenia “Join type” – W tym miejscu optymalizator decyduje jaki typ złączenia zastosować. Najczęściej wybierze taki jaki podamy w zapytaniu jednak nieraz niejawnie wybierze inny np. gdy użyjemy kolumn z tabeli OUTER JOIN w klauzuli WHERE.
Wybór najlepszego planu zapytania dla JOIN
Podczas określania kolejności i metody łączenia celem optymalizatora jest wcześniejsze zmniejszenie liczby wierszy, dzięki czemu wykonuje on mniej pracy podczas wykonywania instrukcji SQL.
Optymalizator generuje zestaw planów wykonania, zgodnie z możliwymi typami, metodami łączenia i ścieżkami dostępu. Optymalizator następnie szacuje koszt każdego planu i wybiera ten o najniższym koszcie. Wybierając kolejność łaczenia tabel optymalizator bierze pod uwagę:
- Optymalizator najpierw określa, czy połączenie dwóch lub więcej tabel powoduje, że źródło wiersza zawiera co najwyżej jeden wiersz. Optymalizator rozpoznaje takie sytuacje po kluczach oraz ograniczeniach UNIQUE na kolumnach. Jeżeli wystąpi taka sytuacja, tabele te są łączone w pierwszej kolejności.
- W przypadku instrukcji OUTER JOIN optymalizator kieruje takie złączenia na koniec. Wyjątkiem są sytuacje gdzie pomimo wpisania w złączeniu OUTER JOIN optymalizator zmienia zapytanie na INNER JOIN.
- Optymalizator sprawdza koszt każdej metody złączenia i wybiera te których koszt jest najmniejszy. Na koszt wpływa przede wszystkim koszt operacji I/O dla pojedynczego bloku jak i wielu bloków oraz koszt CPU. Każda z metod joinowania wymaga zaangażowania innych zasobów.
Czym jest Primary Key
PRIMARY KEY (klucz główny) to kolumna lub kilka kolumn które oznaczają jednoznacznie i unikalnie dany wiersz w obrębie całej tabeli. Każda tabela może mieć jeden klucz główny, który w efekcie nazywa wiersz i zapewnia, że nie istnieją żadne zduplikowane wiersze. Primary key może być naturalny lub wygenerowany. Naturalny oznacza, że same dane gwarantują, unikalność rekordu. Dla przykładu w bazie pracowników kluczem taki może zostać PESEL ponieważ nie ma możliwości aby dwaj pracownicy posiadali taki sam numer pesel. Klucz główny generowany to numer nadawany przez bazę, najczęściej jako kolejne wartości z sekwencji liczbowej. Kolumny które są częścią klucza głównego nie mogą zawierać wartości null.
Dodatkowo należy pamiętać, że przy tworzeniu ograniczenia Primary Key baza danych tworzy na tych kolumnach index unikalny( jeżeli na tych kolumnach nie ma jeszcze indexu) który pozwala szybko przeglądać dane w tabeli.
Więcej o tego typie indexach napisałem w kursie index unique scan
Czym jest Foreign key
FOREIGN KEY (klucz obcy) jest oznaczeniem kolumny lub kilku kolumn jako referencja do kolumn innej lub tej samej tabeli. Referencja ta jest typem relacji w której występuje rodzic i dziecko. Oznacza to, że np. rodzic może mieć wiele dzieci oraz, że każde dziecko może mieć co najwyżej jednego rodzica. Istnieje możliwość zdefiniowania foreign key tak aby wskazywał na null w tabeli rodziców ale nie może wskazywać, na wartość rodzica która nie występuje.
Foreign key występuje w trzech wariantach:
| Wariant | Zachowanie |
| BRAK OPCJI | W sytuacji gdy występują rekordy dzieci do rodziców nie ma możliwości usunięcia rekordu nadrzędnego (rodzica) ponieważ narusza to integralność danych. Wystąpiłaby sytuacja w której posiadamy dziecko z ID do rodzica którego nie ma. |
| DELETE CASCADE | W przypadku tej opcji usunięcie rodzica powoduje usunięcie wszystkich dzieci które posiadają odniesienie do rodzica. |
| DELETE SET NULL | W przypadku tej opcji istnieje możliwość usunięcia rodzica natomiast rekordy dzieci zostaną zamienione na NULL. Dokładniej to kolumny które są odnośnikami (FK) do tabeli nadrzędnej. Nie można użyć tej opcji gdy FK jest NOT NULL. |
Model danych – diagram
Do modelowania bazy danych często wykorzystuje się diagram ERD (Entity relation diagram) który pokazuje zależności pomiędzy poszczególnymi encjami. Poniżej przedstawiony został prosty przykład diagramu z relacją pomiędzy dwoma tabelami.
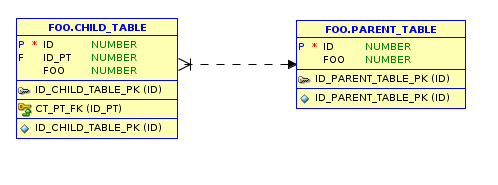
W powyższym diagramie widzimy relację CHILD_TABLE do PARENT_TABLE. Oznaczenie “widełek” wraz z pionową kreską oznacza relację wielu do jednego. Mówiąc prościej wiele rekordów z tabeli CHILD_TABLE może wskazywać na jeden rekord w tabeli PARENT_TABLE.
Podsumowanie
- JOIN to najczęstsza metoda łączenia danych z dwóch i więcej miejsc
- Optymalizator wybiera typ złączenia na podstawie napisanego zapytania
- Optymalizator wybiera metodę łączenia na podstawie danych jakie ma w tabelach/indexach
- Primary key oraz Foreign key służą do zapewnienia integralności danych pomiędzy dwoma tabelami