
W tym kursie opiszę dokładne działanie specjalnego dostępu do danych jakim jest TABLE ACCESS BY INDEX ROWID oraz TABLE ACCESS BY INDEX ROWID BATCHED. W pierwszej kolejności opiszę działania dostępu do tabeli poprzez ROWID oraz czym jest ROWID a następnie pokażę jak mechanizm ten wykorzystuje baza przy korzystaniu z indexu.
ROWID to fizyczny adres miejsca przechowywania danych. Rowid wiersza określa plik danych i blok danych zawierający wiersz oraz lokalizację wiersza w tym bloku. Lokalizowanie wiersza poprzez określenie jego rowid to najszybszy sposób na pobranie pojedynczego wiersza, ponieważ określa on dokładną lokalizację wiersza w bazie danych.
Ten wpis jest częścią Kurs Oracle SQL
Czym jest TABLE ACCESS BY ROWID
Najszybszym możliwym sposobem na dostęp do danych gdy pobieramy jeden konkretny reokord w tabeli jest TABLE ACCESS BY ROWID (bez INDEX).
Aby zobaczyć ROWID wiersza w tabeli bazy wystarczy dodać je do zapytania SELECT jako kolejną pesudokolumnę tak jak w poniższym zapytaniu:
SELECT
ROWID
, T.*
FROM TEST_TABLE T;Oraz wynik powyższego zapytania w którym zobaczymy ROWID
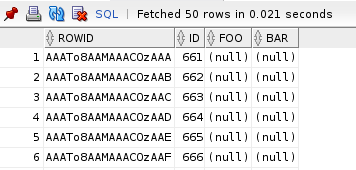
Celowo nie podaję jak utworzyć tabelę ponieważ każdy rekord w każdej tabeli posiada swój ROWID 🙂
Skoro każdy rekord posiada swój unikalny ROWID to można po nim filtrować w klauzuli WHERE. Wtedy zobaczymy w planie zapytania sposób dostępu BY ROWID tak jak w poniższym zapytaniu:
SELECT
*
FROM TEST_TABLE
WHERE ROWID = 'AAATo8AAMAAACOzAAF';
W powyższej tabeli widzimy odwołanie bezpośrednio do tabeli poprzez ROWID. Słowo USER wskazuje, że jest to ROWID podane bezpośrednio przez użytkownika. Jako, że jest to to szybki sposób na dostęp do konkretnego rekordu tabeli to koszt jest odpowiednio mały.
Jak działa TABLE ACCESS BY INDEX ROWID
Skoro wiemy już jak działa metoda dostępu bezpośrednio do tabeli po ROWID jaki ma to związek z INDEXEM?
Po zapoznaniu się z kursem SQL Index w Oralce wiemy, że każdy rekord indexu zawiera indexowane kolumny oraz ROWID rekordu z tabeli. Dzięki ROWID index wie z którym rekordem w tabeli jest bezpośrednio powiązany co pozwala w szybki sposób dostać się do danych z tego wiersza.
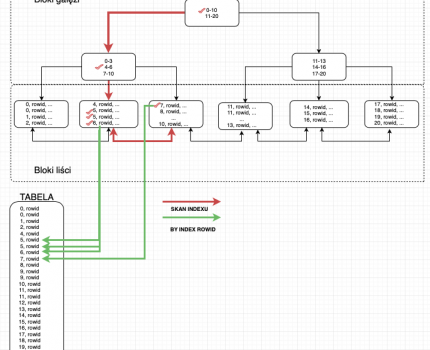
TABLE ACCESS BY INDEX ROWID działa w taki sposób, że w trakcie skanowania w pierwszej kolejności przeszukiwany jest index a następnie barakujące dane (tych których nie ma w indexie) pobierane są z wiersza tabeli. Natomiast dostęp do tabeli następuje po ROWID przechowywanym w Indexie. Poniższy schemat przedstawia jak może wyglądać skanowanie indexu wraz z TABLE ACESS BY INDEX ROWID.
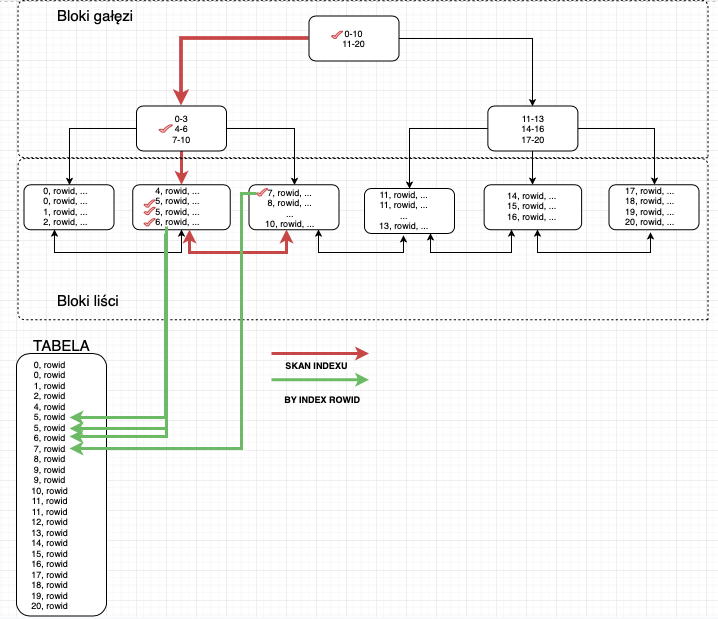
Jak widzimy na powyższym schemacie w pierwszej kolejności przeszukiwany jest index a następnie po ROWID baza danych sięga do danych umieszczonych w tabeli. Skanowanie takie występuje zawsze, gdy w zapytaniu wykorzystamy między innymi kolumny których nie ma w indexie natomiast optymalizator stwierdzi, że najszybszym sposobem filtrowania danych jest wykorzystanie indexu.
Wykorzystanie TABLE ACCESS BY INDEX ROWID
Zobaczmy więc w praktyce kiedy baza użyje table access by index rowid. W tym celu utwórzmy znaną już tabelę TEST_TABLE przy użyciu poniższego skryptu:
CREATE TABLE TEST_TABLE (
ID NUMBER GENERATED ALWAYS AS IDENTITY
, FOO VARCHAR2(255)
, BAR NUMBER
, CONSTRAINT ID_PK PRIMARY KEY (ID)
);Napełnijmy ją danymi:
BEGIN
FOR I IN 0 .. 100000
LOOP
INSERT INTO TEST_TABLE (
FOO
, BAR
) VALUES (
'ACME: ' || MOD(I, 10)
, MOD(I, 100)
);
END LOOP;
END;
/
COMMIT;Oraz przeliczmy statystyki:
EXEC DBMS_STATS.GATHER_TABLE_STATS('SYSTEM','TEST_TABLE');W tym momencie mamy tabelę z trzema kolumnami. Tabela wypełniona jest rekordami w liczbie 100 tyś oraz na tabeli nałożony jest index unikalny na kolumnie ID. O automatycznym tworzeniu indexów na kolumnie z Primary Key pisałem w Kurs Index Unique Scan
Napiszmy więc pierwsze zapytanie w którym wykorzystamy index:
SELECT
ID
FROM TEST_TABLE
WHERE ID = 1000;Oraz plan zapytania:

Na powyższym planie widzimy, że baza wykorzystała metodę UNIQUE SCAN na indexie ID_PK. Nie ma natomiast nic o dostępie do tabeli w jakikolwiek sposób. Wynika to z faktu, że w ramach zapytania (wyświetlenie danych oraz warunki WHERE) wykorzystujemy tylko i wyłącznie kolumnę ID która znajduje się w indexie. W związku z tym, baza nie ma potrzeby sprawdzania danych w tabeli.
Zmieńmy więc w zapytaniu pobierane kolumny z ID na wszystkie kolumny tabeli (*) aby wywołać na bazie poranie danych których w indexie nie ma a są w tabeli:
SELECT
*
FROM TEST_TABLE
WHERE ID = 1000;Oraz plan:

W powyższym planie zapytania widzimy, że baza wykorzystuje dostęp do tabeli TEST_TABLE BY INDEX ROWID. Dokładniej, to baza w pierwszym kroku wyszukuje unikalnego ID=1000 z indexu ID_PK. Po znalezieniu rekordu w indexie odwołuje się do tabeli TEST_TABLE używając ROWID w celu pobrania dodatkowych danych których nie ma w indexie (kolumny FOO, BAR).
Aby pobrać dane niebędące w indexie baza musi wykonać dodatkową operację aby uzyskać dostęp do tych danych znajdujących się w tabeli. W związku z tym, koszt takiego zapytania jest większy niż w przypadku pobierania danych tylko z indexu. Dobrą radą jest za tem nigdy nie wyszukiwać danych przy użyciu * jeżeli ich nie potrzebujemy.
Wykorzystanie TABLE ACCESS BY INDEX ROWID BATCHED
Co jednak dzieje się w sytuacji gdy chcemy pobrać 1000 rekordów. Czy w tej sytuacji bazie bardziej opłacać się, będzie pobranie 1000 rekordów z indexu a następnie 1000 razy szukać w tabeli rekordów po rowid oraz 1000 razy pobierać bloki danych dla pojedyńczego rekordu czy może bezpośrednio przeszukać tabelę i znaleźć w niej potrzebne rekordy?
Aby poprawić wykonywanie zapytań które pobierają większą ilość rekordów Oracle od wersji 12c wprowadził nowy typ skanowania: TABLE ACCESS BY INDEX ROWID BATCHED. Oznacza on, że baza podczas skanowania pobiera z indexu rowid z tego samego bloku a następnie wyszukuje je w tabeli. Paczkami po kilkanaście na raz. Dzięki zastosowaniu tego typu skanowania baza poprawia szybkość pobeirania danych z tabeli ponieważ przy pomocy jednej operacji pobiera dane dla wielu rekordów.
Ten typ skanowania wykorzystywany jest najczęściej gdy w warunku WHERE użyjemy operatorów które zwracają więcej rekordów niż jeden. Spróbujmy więc zmienić ostatnie zapytanie tak aby pobrał większą ilość rekordów poprzez zmianę operatora na > oraz zmianę zakresu danych:
SELECT
*
FROM TEST_TABLE
WHERE ID > 90000;Oraz plan zapytania:

Na powyższym planie zapytania widzimy, że baza w pierwszej kolejności wykona RANGE SCAN na indexie ID_PK w celu pobrania więcej niż jednego rekordu a następnie “paczkami” pobierze resztę danych z tabeli TEST_TABLE.
Podsumowanie
- ROWID jest unikalnym adresem rekordu w tabeli
- Dostęp do tabeli po ROWID jest bardzo szybki
- TABLE ACCESS BY INDEX ROWID oznacza, że zapytanie po znalezieniu rekordów w indexie pobiera brakujące dane z tabeli przy użyciu ROWID rekordu tabeli
- TABLE ACCESS BY INDEX ROWID BATCHED oznacza, że zapytanie po znalezieniu rekordów w indexie pobiera brakujące dane z tabeli przy użyciu ROWID rekordów z tabeli paczkując je i pobierając wiele na raz.
- TABLE ACCESS BY INDEX ROWID jest wolniejsze niż pobranie danych z samego indexu
- Jeżeli nie ma potrzeby nie używajmy * w kaluzuli SELECT
Jeśli chcesz być na bieżąco polub stronę OracleDev na facebooku: